
“We wrestle on Twitter. The battle is on Facebook. The war is on WhatsApp” — the likelihood that sentiments like these won’t be confined to party strategists from India is increasingly clear. Usage of WhatsApp, Signal, WeChat, Telegram, Line and other closed messaging spaces is on the rise.
According to the 2018 Digital News Report issued by the Reuters Institute of the University of Oxford, people surveyed (74,000 online news consumers in 37 countries) have been using messaging apps more for any purpose (44%), and average usage for news in these spaces has more than doubled to 16% in four years.
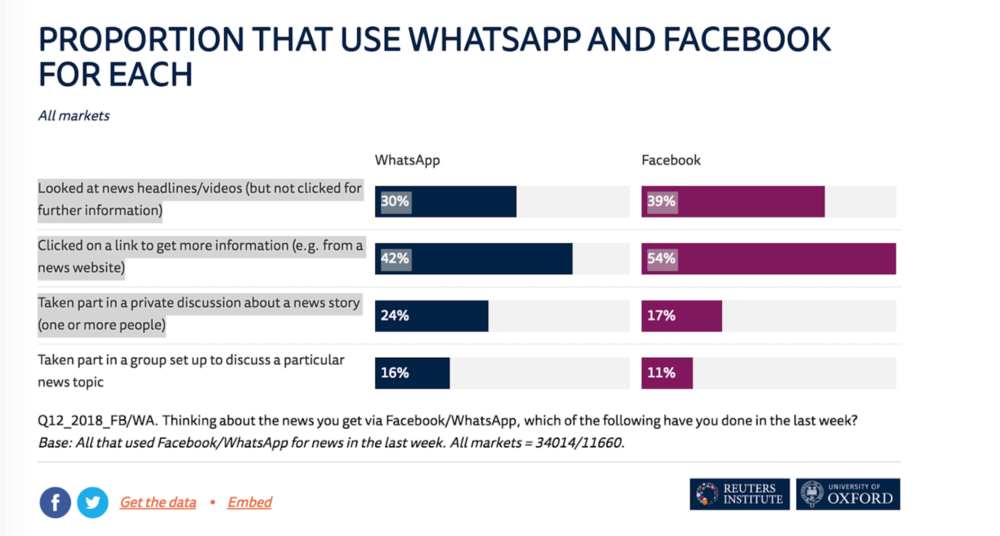
From “The Rise of Messaging Apps for News,” Digital News Report, Reuters Institute for the Study of Journalism, 2018.
The reason for this shift is straightforward enough: an increased desire for privacy, which is exactly why the spaces are not yet well understood. Data related to these conversations are available to participants only, which could be as small a space as between you and another, or perhaps among a small set of family and friends, and as large as hundreds.
This isn’t necessarily bad. The move to more private conversations or away from public conversations could be a cause of concern in terms of the deliberation that democracy requires. Or it could be just fine: perhaps more discussion of news topics is better no matter where it happens; perhaps more private discussion leads to fewer, but better formed civic conversations. It’s hard to say. We just don’t know enough.
So we were inspired by the recent call by WhatsApp to encourage more investigation into this space. We wanted to inquire about two things, which exist in apparent tension: what are the good methodologies to explore this space — in which one could expect reliable data? And what ethics of the situation need to be taken into account, given the very privacy that grounds these spaces?
We were fortunate enough to host this workshop with Oren Levine from the International Center for Journalists, who stressed the urgency of this topic, given the increasing use of WhatsApp as a primary channel for recording and sharing news. We broke apart in groups and had some lively discussion, and came away with a few thoughts.
1. We need to gather more information about what sort of content gets shared and who shares it.
Because these spaces are private, any knowledge about them requires the participation of people using private messaging apps. It’s easy to imagine an opt-in survey form for those willing and interested, as a simple way to get more information about how they’re engaging on private chat apps, who they are, and whether they might be interested in an ongoing study.
Our qualitative understanding of the landscape of messaging groups and the content that gets shared could increase based on responses to these surveys. One questionnaire might include the following questions, say in response to a broad research call for sample private messages that include misinformation:
- What language is the message in?
- Select the scale of the private message group you found the message: 2 people, 3–5 people, 5<x <100, 100+
- Describe focus of the group, if applicable: family, friends, organization, cause
- Do you have a screenshot of message that you can provide?
- Date of message share
- Contributor contact: Email or whatsapp contact number to answer questions
- Willingness to answer a few more questions? Y/N
If the submitter was willing, we could then also ask a little bit more about the participant as a way of understanding the people who share within this space.
For instance, they could fill out another survey about contributors, anonymized but providing a certain amount of demographic and user experience data:
- Age range
- Gender
- Country
- Political Spectrum
- Economic Spectrum
- Race/Ethnicity
- How many years have you been using WhatsApp? less than a year, one year, several years
- When do you use WhatsApp?
In the end, collecting and comparing this information across country contexts and languages could provide us better understanding of what’s going on in these spaces.

2. Before deploying surveys or other research, think about the limits of what knowledge could be reliably gathered.
In addition to descriptive information via survey, we could re-purpose something as simple as fact-checking “hotlines” or “tiplines” (such as recently in Mexico, upcoming Brazil, and long-running in Taiwan) — a number that people could forward relevant content to through their private message apps — for research. In this case, donations of problematic messages along with some additional context could further contribute to our understanding of these spaces.
However, with voluntary surveys solicited through private spaces, the likelihood that responses might be less than authentic was raised at the outset. In other words, maybe people will submit surveys with dummy information, just because they can. This ended up suggesting that the less anonymous the participant is, the more trusted the responses. Perhaps better chains of connections between researcher and those studied means better knowledge.
Right off the bat, though, this means that our knowledge of these spaces will not scale. Based on trusted networks, efforts would also not likely produce super diverse sets of participation: it’s hard to imagine participation by private messaging groups that discuss illegal topics, or say, anti-democratic ones.

An example of collective ideas gathered on this topic using our favorite “workshop with (big) stickies” model.
3. The bar for ethical review may need to be higher than average, given the context.
Trying to increase quality through a trusted participant chain also raises the issue of ethics. For example, we might leverage our own networks, but that immediately raises obligations to our friends and families.
We also have to think about de-identification and anonymization of this data (this recent Guardian story provides some good examples of what happens when it’s not done properly).
What about buy-in in terms of the people we’re talking to — to what extent should they have a say in shaping what gets reviewed, analyzed, and saved even after the fact?
In addition, we’d have to minimally disclose our intent, our privacy policies, and try to find external reviewers to help keep our processes straight, so who could help us do this?
Finally, what’s the role of the researcher here, especially if he or she is actively trying to breach private spaces? Certainly, one has gone beyond simple observation and any related observer effects. And what about safety considerations for these reporters and researchers as well?
Let’s repeat: we really, really have to think about de-identification and anonymization of this data.
We also need to understand what consent looks like when (1) the individual submitting a piece of content might not represent the entire group from which it came or when (2) clearly stating that one is a journalist might get one expelled from certain groups or even targeted for harassment.
In any case, these were some of the thoughts we came to in Washington DC, and we’d love to hear other ideas on this and continued brainstorming. In our next post, we’ll talk about our workshop on nutrition labels for news.
MisinfoCon 4.0 in Washington, D.C. was the fourth gathering of the Misinfocon community, a project of the Hacks/Hackers Foundation. Through meetings around the world, plus writing and social media, Misinfocon is focused on finding ways to counter misinformation and its effects by improving trust, verification, fact checking and the reader experience.
This is the second in a series of blog posts from the Credibility Coalition reflecting on workshops we led at MisinfoCon D.C., held at the Newseum. We conducted these workshops over the course of two days, with about 50 people in attendance from a variety of organizations representing government, research, advocacy, journalism and academic groups.
This post was originally published on Misinfocon’s Medium page. It was republished on IJNet with permission.
Main image CC-licensed by Unsplash via Kelly Sikkema.