
بعدما تعرفنا في مقال سابق بعنوان "التنقيب في البيانات النصية.. عمَّ نبحث في النصوص؟" على طبيعة المعلومات التي يمكن استخراجها من البيانات النصية غير المهيكلة، والتي يمكن أن تساعدنا في تحليل النصوص واستخراج حقائق تقود لاكتشاف قصص صحفية معمقة، ننتقل في هذه المقالة إلى الخطوة التالية في عملية تحليل البيانات النصية، وهي تنظيف البيانات.
تنظيف البيانات النصية، أو كما يطلق عليها علماء البيانات "المعالجة المسبقة للبيانات" يعني التخلص من الأخطاء الهيكلية التي قد تكون وقعت أثناء عملية إدخال البيانات أو تحويلها من صيغة إلى أخرى. كما يشمل التخلص من الأجزاء التي لا تضيف أي معنى للنص، مثل علامات الترقيم أو الكلمات المتكررة أو الأحرف غير الملائمة بهدف تقليل التشويش في النص. وأثبتت الكثير من المنشورات البحثية فوائد المعالجة المسبقة وأهميتها في تحسين دقة أداء نماذج الذكاء الاصطناعي.
هناك أنواع مختلفة من الضوضاء التي يمكن أن تكون موجودة في البيانات النصية. يمكن أن تختلف أنواع الضوضاء هذه في طبيعتها وحجمها، ويمكن أن تؤثر بشكل كبير على جودة ودقة البيانات النصية. ومن خلال فهم أنواع الضوضاء ومعالجتها بشكل صحيح، يمكننا تحسين أساليب تحليل البيانات النصية ومعالجتها.
فيما يلي أنواع التشويش الشائعة في البيانات النصية والاستراتيجيات المتبعة للتخفيف من تأثيرها:
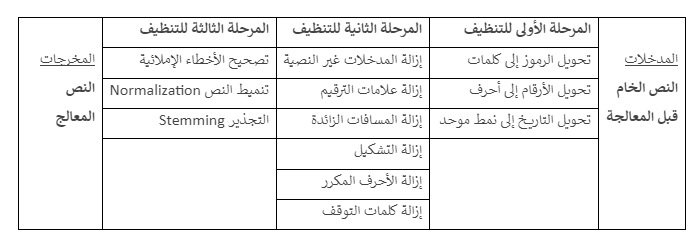 تحويل الرموز إلى كلمات: في النصوص التي تأتي من مصادر بديلة – غير رسمية - لا تتسم اللغة فيها بمعايير الكتابة الرسمية مثل منشورات منصات التواصل الاجتماعي، قد تتضمن في كثير من الحالات رموزًا تعبيرية، تعبر عن المشاعر وربما تستخدم لغرض اختصار مساحة الكلمات لتخطي قيد عدد الكلمات الذي تضعه منصات التواصل الاجتماعي مثل منصة X، يمكن استبدال تلك الرموز بما يقابلها من نص، مثل رمز القلب بكلمة "حب" ورمز الوجه الغاضب بكلمة "حزن" كذلك تحويل الرمز & إلى كلمة "و" و الرمز % إلى كلمة "بالمئة".
تحويل الرموز إلى كلمات: في النصوص التي تأتي من مصادر بديلة – غير رسمية - لا تتسم اللغة فيها بمعايير الكتابة الرسمية مثل منشورات منصات التواصل الاجتماعي، قد تتضمن في كثير من الحالات رموزًا تعبيرية، تعبر عن المشاعر وربما تستخدم لغرض اختصار مساحة الكلمات لتخطي قيد عدد الكلمات الذي تضعه منصات التواصل الاجتماعي مثل منصة X، يمكن استبدال تلك الرموز بما يقابلها من نص، مثل رمز القلب بكلمة "حب" ورمز الوجه الغاضب بكلمة "حزن" كذلك تحويل الرمز & إلى كلمة "و" و الرمز % إلى كلمة "بالمئة".
| نسبة النجاح 90% & نسبة الفشل 10% | نسبة النجاح 90 بالمئة ونسبة الفشل 10 بالمئة |
عند معالجة النصوص آليًا، قد يهمش الحاسوب الرموز ويعطي الأهمية للنص لأنّ الخوارزميات في هذه الحالة قد حُضّرت للتعامل مع النصوص وتجاهل أي شي آخر، لذلك ينبغي معالجة الرموز بشكل مسبق وتحويلها إلى ما يرادفها من كلمات إذا كانت هذه الرموز ذات أهمية دلالية في النص ولا يمكن حذفها أو تجاهل ما تعبر عنه من معنى.
فكر في هذا المثال: "أنا أحب 🍕 و 🍔، لكن 😥 لا أستطيع تناولهم اليوم، لأنني في رحلة ✈️ طويلة." هل يمكن حذف الرموز والاكتفاء بالنص، أم أن عملية تحويل الرموز إلى نصوص ضرورية؟
تحويل الأرقام إلى أحرف: في بعض الأحيان، تكون الأرقام غير ضرورية لتحليل النصوص، وقد يكون من الأفضل تحويلها إلى أحرف. على سبيل المثال، يمكن تحويل الرقم "100" إلى كلمة "مئة" مثلا إذا كان النص هو "لدي 100 تفاحة" سيكون "لدي مئة تفاحة" فالأعداد بشكلها الرقمي مفيدة في التحليلات الاحصائية القائمة على العمليات الحسابية لكن عندما يتعلق الأمر بتحليل النصوص فمن الأفضل أن يتم تحويلها لحروف.

باستخدام مكتبات مثل num2words أو كتابة دالة مخصصة، يمكننا تحسين جودة النصوص وجعلها أكثر وضوحًا وقابلية للتحليل.
تنميط التواريخ: هو جزء مهم من تنظيف البيانات النصية، حيث يمكن أن تكون التواريخ مكتوبة بصيغ مختلفة، وتُستخدم العديد من أنماط كتابة التواريخ، بعضها أكثر شيوعًا من غيرها، مثل:
MM/DD/YYYY (النمط الأميركي): 10/26/2023
DD/MM/YYYY (النمط الأوروبي): 26/10/2023
DD-MM-YYYY (النمط البريطاني): 26-10-2023
YYYYMMDD (النمط الرقمي): 20231026
DD MMM YYYY (النمط اللفظي): 26 أكتوبر 2023
MMM DD, YYYY (النمط اللفظي المختصر): أكتوبر 26، 2023
عند تحليل البيانات الزمنية، مثل الاتجاهات أو الأنماط على مر الزمن، يمكن أن يؤدي عدم توحيد التواريخ إلى نتائج غير دقيقة أو مضللة. التنميط يساعد في ضمان أن تكون جميع التواريخ مفهومة ومعالجة بشكل صحيح. لذلك يعد تنميط التواريخ خطوة أساسية في تنظيف البيانات النصية لتحسين جودة البيانات وجعلها أكثر قابلية للتحليل. باستخدام مكتبات مثل dateutil أو كتابة دوال مخصصة، يمكننا تحويل التواريخ المكتوبة بصيغ مختلفة إلى صيغة موحدة مما يسهل عمليات التحليل اللاحقة.
إزالة المدخلات غير النصية: تشمل المدخلات غير النصية الروابط، والإشارات مثل "@". يمكن إزالة هذه المدخلات ببساطة للتركيز على النص الأساسي، كما يمكن أيضًا في هذه الخطوة التخلص من النصوص بأي لغة أخرى بخلاف اللغة الأساسية للملف.

تصبح المدخلات غير النصية قليلة الأهمية بحسب الغرض من تحليل البيانات النصية، فمثلًا لتحليل المشاعر أو نمط الخطاب قد نكتفي بالتركيز على النصوص لتحديد إلى أي تصنيف ينتمي النص، كذلك الحال عن إنشاء نماذج تحديد الموضوع Topic Modeling باستخدام الأدوات والمكتبات المناسبة في بايثون مثل re وlangdetect، يمكن تنفيذ هذه الخطوات بكفاءة، مما يساعد في تحسين جودة البيانات النصية.
إزالة علامات الترقيم: قد تؤثر علامات الترقيم مثل النقاط والفواصل والأقواس على تحليل النصوص. لذا، يتم استبعادها عادةً في عملية إزالة الضوضاء، فمثلًا هذه العبارة بين علامتين التنصيص تحتوي على الكثير من علامات الترقيم "هذا، هو! مثال رائع". والتي تسهل على القارئ فهم المعنى وقراءة العبارة بسهولة، وهو أمر مختلف بالنسبة للحاسوب الذي يتعامل مع الكلمات منفردة في سياق منفصل أولًا قبل أن يشكل فهمًا عميقًا للسياق الكلي، لذا فالحاسوب سوف ينظر إلى هذه العبارة على أنها مكونة من 7 كلمات في حين أنّ حذف علامات الترقيم سيجعلها تحتوي فقط على 4 كلمات وهو ما يساهم في تقليص حجم المدخلات لنماذج الذكاء الاصطناعي التي تركز فقط على الكلمات ذات الدلالة وتهمش الكلمات الأقل تأثيرًا في النص.

بالنسبة للبشر، علامات الترقيم تساعد في فهم النص وتقسيمه إلى جمل وأجزاء مفهومة، لكن بالنسبة للأنظمة الحاسوبية التي تعالج النصوص، فإنها قد تضيف تعقيدًا غير ضروري.
إزالة علامات الترقيم تُسهم في تحسين جودة التحليل من خلال عدة فوائد:
- تقليل حجم المدخلات: تُقلل إزالة علامات الترقيم من عدد الرموز في النص، مما يُقلل من حجم المدخلات للنماذج الحاسوبية.
- تبسيط المعالجة اللغوية: تجعل إزالة علامات الترقيم النصوص أكثر بساطة، مما يُسهل على الخوارزميات فهم وتحليل الكلمات الفردية بدون الحاجة إلى التعامل مع رموز غير ضرورية.
- تحسين دقة التحليل: تُسهم إزالة علامات الترقيم في تحسين دقة النماذج اللغوية، وخصوصًا في تحليل النصوص وتصنيفها، حيث تُقلل من التشويش الناتج عن الرموز غير اللفظية.
إزالة المسافات الزائدة: المسافات الزائدة هي مسافات إضافية غير ضرورية بين الكلمات أو العبارات في النص تُستخدم أكثر من مرة بين الكلمات، بدلاً من استخدام مسافة واحدة فقط يُمكن أن تكون ناتجة عن أخطاء إملائية أو عن استخدام برامج تحرير نصوص غير مناسبة. إزالتها خطوة مهمة في عملية تنظيف البيانات النصية، حيث قد يتسبب وجودها في تعطيل التحليل الصحيح للنصوص، لتؤدي إلى تفسيرات غير صحيحة للكلمات والجمل، وتؤثر على دقة النماذج التحليلية. يوضح المثال التالي الجملة التي تحتوي على مسافات خاطئة زائدة مقارنة بالوضع الصحيح بعد التنظيف.
 تؤدي المسافات الزائدة إلى:
تؤدي المسافات الزائدة إلى:
- فقدان السلاسة: تُصبح الجملة متقطعة وغير سلسة في القراءة، مما يُشكل صعوبة في فهم المعنى.
- التباس: قد تُفهم الجملة بشكل مختلف بسبب وجود المسافات الزائدة، مما يُؤدي إلى التباس في المعنى.
- التشويه: تُصبح الجملة مشوهة وغير طبيعية، مما يُقلل من جمالية اللغة.
إزالة التشكيل: في اللغة العربية، التشكيل (الحركات مثل الفتحة والضمة والكسرة والسكون) يستخدم لتوضيح النطق الصحيح للكلمات. ومع ذلك، في بعض التطبيقات النصية مثل معالجة النصوص الطبيعية (NLP)، قد يكون من الأفضل إزالة التشكيل لتبسيط النص وتقليل التعقيد، مما يساعد في تحسين أداء النماذج التحليلية وتقليل حجم البيانات.
 حذف الأحرف المكررة: قد يحتوي النص على أحرف متكررة بشكل غير ضروري. يمكن حذف هذه الأحرف المكررة لتسهيل عملية تحليل النص، مثلًا تلك العبارة "مرحبااااا بالعالم" والتي تحتوي على تكرار زائد لحرف الألف في نهاية الكلمة الأولى وتجعل من هذه الكلمة مختلفة عن كلمة مرحبا الصحيحة مما يجعل نماذج الذكاء الاصطناعي تتعامل مع الكلمتين كمدخلين منفصلين مختلفين غير متطابقين، وهذا يتنافى مع الهدف الأساسي الذي يسعى إليه علماء البيانات عند إنشاء نماذج الذكاء الاصطناعي لمعالجة اللغات الطبيعية، حيث يكون هدفهم الأول هو تقليص عدد المدخلات.
حذف الأحرف المكررة: قد يحتوي النص على أحرف متكررة بشكل غير ضروري. يمكن حذف هذه الأحرف المكررة لتسهيل عملية تحليل النص، مثلًا تلك العبارة "مرحبااااا بالعالم" والتي تحتوي على تكرار زائد لحرف الألف في نهاية الكلمة الأولى وتجعل من هذه الكلمة مختلفة عن كلمة مرحبا الصحيحة مما يجعل نماذج الذكاء الاصطناعي تتعامل مع الكلمتين كمدخلين منفصلين مختلفين غير متطابقين، وهذا يتنافى مع الهدف الأساسي الذي يسعى إليه علماء البيانات عند إنشاء نماذج الذكاء الاصطناعي لمعالجة اللغات الطبيعية، حيث يكون هدفهم الأول هو تقليص عدد المدخلات.

تتم إزالة كلمات الوقف عادةً باستخدام مكتبات البرمجة التي تدعم معالجة النصوص. تشمل بعض الأدوات الشائعة:
- NLTK Natural Language Toolkit: مكتبة في بايثون توفر قوائم مسبقة من كلمات الوقف وتسمح بإزالتها بسهولة.
- spaCy: مكتبة أخرى في بايثون تُستخدم لمعالجة اللغة الطبيعية وتقدم أدوات فعالة لإزالة كلمات الوقف.
- scikit-learn: مكتبة تتضمن طرقًا لتحويل النصوص إلى تمثيلات عددية مع إمكانية تجاهل كلمات الوقف.
تنميط النص: هذه الخطوة تتضمن تحويل الأحرف النصية إلى نمط موحد. يمكن استخدام تقنيات مثل تحويل الحروف إلى صيغة صغيرة أو كبيرة وذلك في اللغة الانجليزية مثال: "Text" يصبح "text" لجعل الكلمات جميعها مكتوبة بأسلوب موحد، واستخدام تنسيقات موحدة الأرقام والتواريخ كما أشرنا في نقاط سابقة، وتحويل الأحرف غير الأبجدية إلى أحرف بديلة (على سبيل المثال، "é" إلى "e") في اللغة العربية يتم تحويل كافة أشكال حرف الألف على سبيل المثال إلى رسم موحد وكذلك الهاء والتاء المربوطة وحرف الياء. تحويل جميع أشكال الألف (أ، إ، آ) إلى شكل موحد (ا).
 التجذير: التجذير هو عملية تحويل الكلمة إلى أبسط شكل لها، وهو الجذر الذي يُمثل المعنى الأساسي للكلمة بغض النظر عن اللاحقات أو البادئات التي قد تكون مُضافة إليه. حيث يشير التجذير إلى تحويل الكلمات إلى جذورها الأساسية. هذا يساعد في تجميع الكلمات التي لها نفس الأصل وتحليلها ككل، يساعد التجذير في تجميع الكلمات التي لها نفس الأصل، مما يسهل تحليلها. على سبيل المثال، يمكن تجذير الكلمات "سعيد"، "سعادة"، و"أسعد" إلى الجذر "س ع د"، والكلمات "كتب"، "يكتب"، و"مكتوب" يتم تجذيرها إلى الجذر "ك ت ب".
التجذير: التجذير هو عملية تحويل الكلمة إلى أبسط شكل لها، وهو الجذر الذي يُمثل المعنى الأساسي للكلمة بغض النظر عن اللاحقات أو البادئات التي قد تكون مُضافة إليه. حيث يشير التجذير إلى تحويل الكلمات إلى جذورها الأساسية. هذا يساعد في تجميع الكلمات التي لها نفس الأصل وتحليلها ككل، يساعد التجذير في تجميع الكلمات التي لها نفس الأصل، مما يسهل تحليلها. على سبيل المثال، يمكن تجذير الكلمات "سعيد"، "سعادة"، و"أسعد" إلى الجذر "س ع د"، والكلمات "كتب"، "يكتب"، و"مكتوب" يتم تجذيرها إلى الجذر "ك ت ب".
التجذير هو عملية حيوية في معالجة النصوص الطبيعية، يساعد في تقليل التباين في النصوص وتحسين دقة التحليل. باستخدام تقنيات متقدمة للتجذير، يمكن تحقيق نتائج أفضل في تحليل النصوص، وتحليل المشاعر، واستخراج المعلومات. التجذير يسهم في جعل النصوص أكثر تجانسًا، مما يعزز فعالية النماذج التحليلية والتطبيقات المختلفة.
بعد استعراض الخطوات الأساسية لتنظيف البيانات النصية، يتضح لنا أن هذه العملية تُعد جزءًا لا يتجزأ من تحليل النصوص واستخراج المعلومات منها بشكل فعال. من خلال إزالة الضوضاء وتنظيم البيانات، يمكننا تحسين دقة النماذج التحليلية وتقديم نتائج أكثر وضوحًا وقابلية للاستخدام. ليست مجرد عملية روتينية، بل هو فن وعلم في آن واحد. يتطلب مزيجًا من المهارات التقنية والفهم العميق للنصوص لتحقيق أفضل النتائج.
يساعد تنظيف البيانات الصحفيين والمحللين على استخراج قصص وتحليلات معمقة وموثوقة من البيانات النصية المتاحة، مما يُعزز من جودة التحليل ويُساهم في تقديم تقارير وأبحاث دقيقة وذات مصداقية عالية. ولكن، لا يخلو هذا المجال من التحديات. تُشكل اللغات المختلفة تحديًا كبيرًا، حيث تختلف قواعدها النحوية وعلامات الترقيم ومفرداتها بشكل ملحوظ. كما تُشكل البيانات النصية غير المنظمة، مثل التغريدات والرسائل والمدونات، تحديًا بسبب أخطائها الإملائية وعلامات الترقيم غير المنتظمة وكلماتها غير ذات الصلة. وتُمثل اللغة العامية والاختصارات التي تُستخدم في المحادثات والرسائل تحديًا إضافيًا، حيث تختلف عن اللغة المعيارية وتُصعب فهمها من قبل أنظمة التحليل.
رغم هذه التحديات، تُعدّ عملية تنظيف البيانات النصية ضرورية لتحقيق نتائج تحليلية دقيقة وموثوقة. في النهاية، يُمكن القول بأن تنظيف البيانات النصية هو خطوة أساسية لتحليل البيانات النصية واستخراج المعلومات القيمة منها، مما يُساهم في تحسين فهمنا للعالم من حولنا. فمن خلال تنظيف البيانات، يمكننا تحويل البيانات الخام إلى معلومات قابلة للاستخدام، مما يُساعدنا على اتخاذ قرارات أكثر دقة وفهم العالم بشكل أفضل.
في الختام يمكنكم الاطلاع على هذا الكود البرمجي لاكتشاف الخطوات التطبيقية لعملية تنظيف البيانات، وكذلك تصفح هذا المورد التعليمي الذي أعدته جامعة نيويورك بخصوص المعالجة المسبقة للنصوص باللغة العربية.
الصورة الرئيسة حاصلة على رخصة الاستخدام على أنسبلاش بواسطة ماركوس سبايسكي.
阅读的其他作品
