
Using data in your reporting allows you to find stories more hidden from view and create visualizations that more fully engage audiences.
But first, you’ll need your numbers in a friendly, usable format. After all, data sets are often trapped in PDFs or on websites, which can make it difficult for journalists to analyze them for their reporting. To do so, you’ll need to “scrape” the data from these sources and then convert it into a format that will let you search, sort and filter the information.
There are many ways to scrape data. In this post we examine two simple tools that don’t require any knowledge of programming or coding to use. And, they're free.
Scraping data from a web page
When we come across data we’d like to extract from a web page, the tendency is to try to copy and paste it directly onto an Excel spreadsheet. This approach, however, usually doesn’t work so well.
This is where Table Capture can help. This free Google Chrome extension allows you to copy tables in HTML format from the web and paste them into Microsoft Excel, Open Office or Google Sheets.
In the example below, we use Table Capture to scrape data about tuberculosis from TBFacts, a site that publishes free data about the disease, onto Google Sheets.
1) To get started, you’ll need to install the Table Capture application from the Chrome Web Store. After doing so, you’ll be able to access it from the top right hand corner of your browser. The arrow in the image below points to the Table Capture icon.
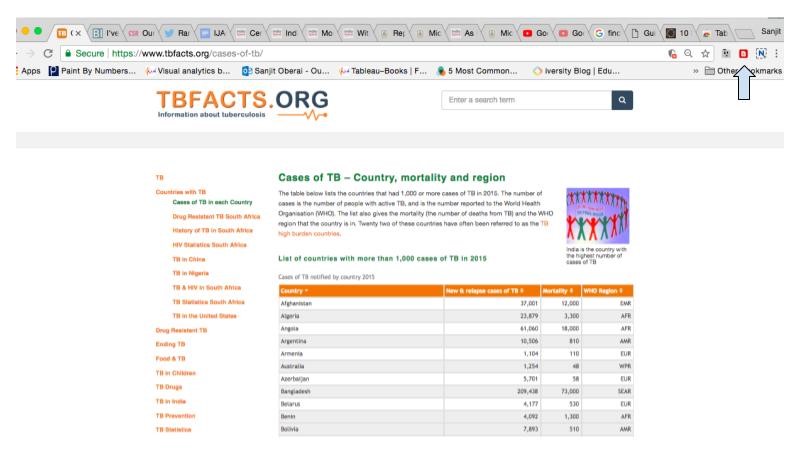
2) The Table Capture icon turns from black to red when it detects HTML tables on a website. Clicking on the red icon opens a drop down menu that shows you the data on the web page that you are able to copy. In this example, there is one table containing data that you can extract.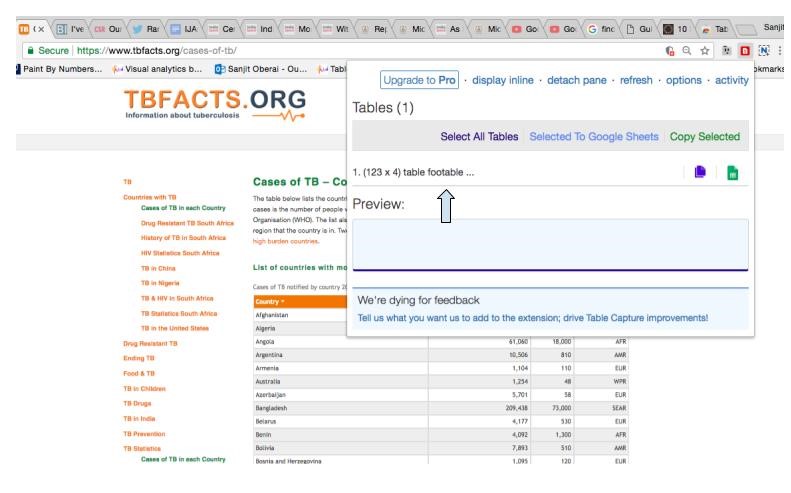
3) To extract this data set, first click on “(123 x 4)” in the drop down menu — this will automatically select and copy the data. Then, click on the green sheet icon in the top right of the drop down menu to open Google Sheets and paste the data onto the spreadsheet.
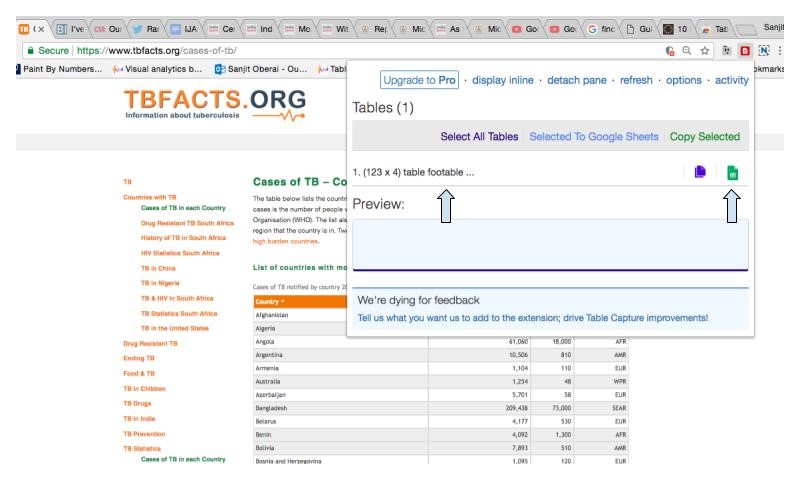
Note: If a web page has multiple tables, clicking “Select All Tables” allows you to copy them all at once.
Scraping data from a PDF
If you’re looking to scrape data from a PDF onto a spreadsheet, Tabula is another easy-to-use, free tool. Tabula works with text-based PDFs — the tool is not compatible with PDF documents that have been scanned. Let’s try it out!
1) Download and install Tabula on your computer. The download link is available on Tabula's website. The software is compatible with both PCs and Macs.
2) When you open Tabula, you will see a blue “Browse” button. Click this button to select the pdf file you want to upload from the computer, which should take 20-30 seconds to complete. The file will be added to the “Imported PDFs” list you see in the image below.
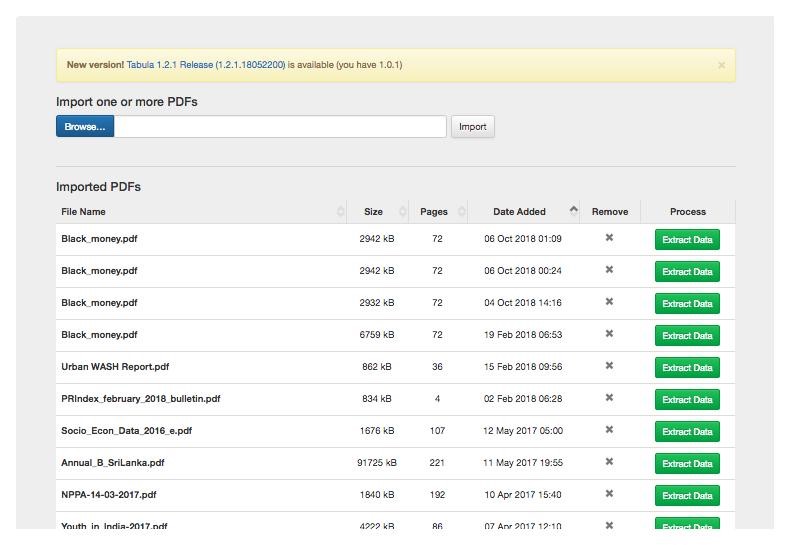
3) Tabula shows you a preview of the PDF you imported. Scroll through the pages to find the data that you would like to scrape.
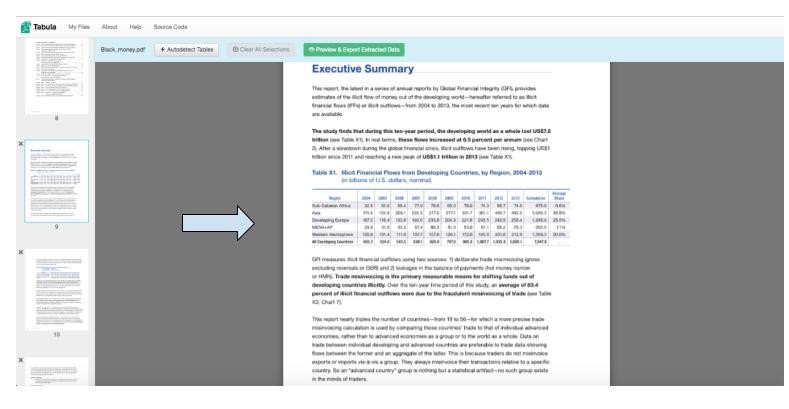
4) Click and drag your cursor over the table you’d like to scrape from. Tabula will highlight your selection in red.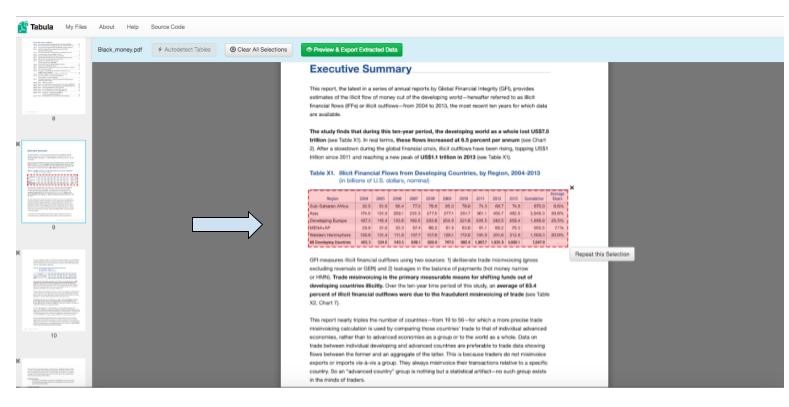
5) Click the green “Preview & Export Extracted Data” button at the top of the page.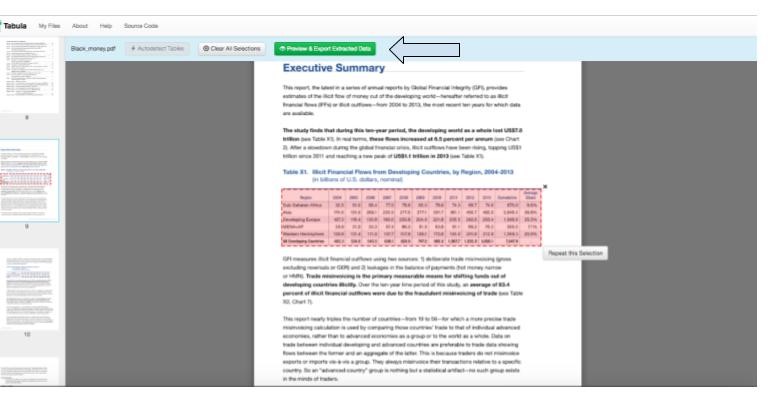
6) Tabula shows you a preview of the selected data. Select the CSV export format. CSV, which stands for comma separated values, is a common, easy-to-use file format.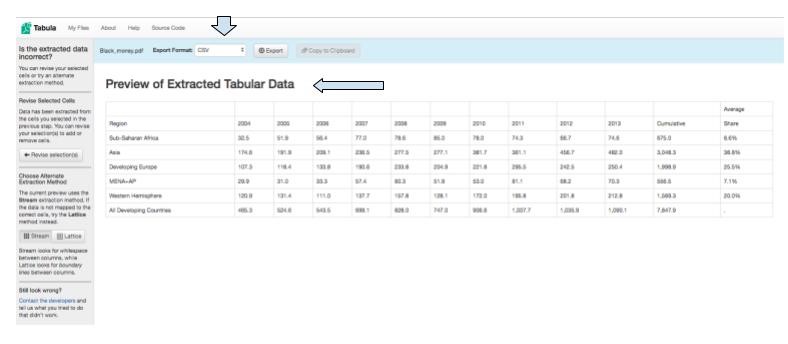
7) Click “Export” and the CSV file will download to your computer.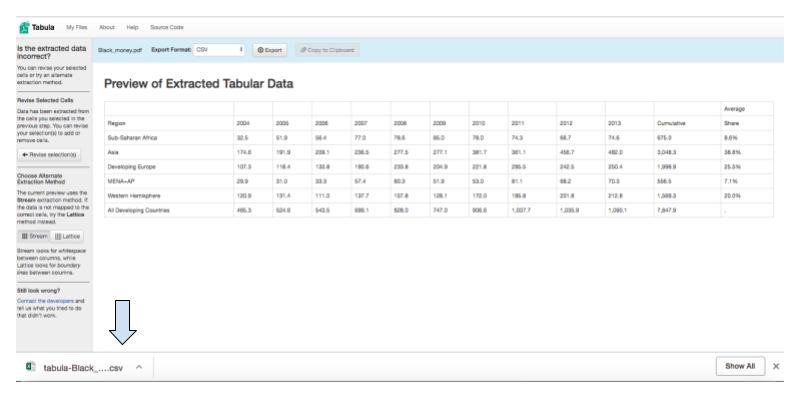
8) Open the file, and the data will be ready and waiting for you to analyze in Excel.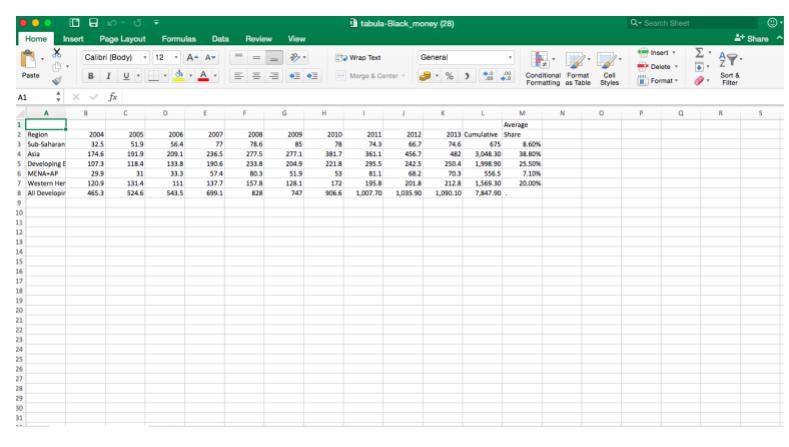
Scraping data doesn’t have to be complex or intimidating — and it can be hugely beneficial to finding those hidden stories that might otherwise go unnoticed. Table Capture and Tabula are great for first-time scrapers, and they have more to offer after you learn the basics too. So, feel free to experiment.
Happy scraping!
Sanjit Oberai is a former ICFJ Knight Fellow. He is based in India and works with PROTO.
Main image CC-licensed by Unsplash via Markus Spiske.