
في غرف الأخبار، لا نواجه فقط سيلًا متصلًا من المعلومات، بل نخوض معركة مستمرة لفصل الصالح من الطالح، وتصنيف المعلومات الواردة إلينا وفقًا لمعايير تحريرية واضحة. هل هذه القصة الإخبارية دقيقة أم مفبركة؟ هل هذا الخطاب يحمل نبرة تحريضية أم هو تعبير مشروع عن الرأي؟ هل المنشور يتوافق مع السياسات التحريرية للمؤسسة أم يجب تعديله أو حتى حذفه؟
هذه الأسئلة، التي كانت في الماضي تعتمد بالكامل على الخبرة الصحفية والحدس التحريري، باتت اليوم تستنزف وقت الصحفيين وجهدهم في ظل تصاعد حجم الأخبار وانتشار التضليل الإعلامي. لكن ماذا لو كان بإمكان الذكاء الاصطناعي أن يتحمل جزءًا من هذا العبء.
هنا، تبرز الحاجة إلى نماذج الذكاء الاصطناعي القادرة على القيام بمهمة التصنيف وفرز المحتوى بدقة وسرعة، ما يسمح للمؤسسات الصحفية بالحفاظ على معاييرها التحريرية، وتعزيز كفاءتها التشغيلية، ومواجهة التحديات التي فرضها العصر الرقمي.
نماذج التصنيف
في مجال تعلم الآلة (Machine Learning)، تُعتبر نماذج التصنيف (Classification Models) من أكثر الأدوات استخدامًا، خاصةً في تحليل البيانات النصية، مثل الأخبار ومقالات الرأي. يعتمد نموذج التصنيف على تعلُم الأنماط الموجودة في البيانات المبوبة مسبقًا (Labeled Data) ليتمكن لاحقًا من تصنيف البيانات غير المبوبة تلقائيًا، بناء على ما تعلمه عن سمات كل تبويب أثناء عملية التعلُم الموجه.
ببساطة: لنتخيل أننا أمام إناء يحتوي على كرات ذات لونين: برتقالية وزرقاء، ونحن بحاجة إلى فرزها إلى إناءين منفصلين. يمكننا فعل ذلك يدويًا، ولكن الأمر سيستغرق وقتًا طويلاً، بينما يمكننا بناء نموذج تصنيف آلي نُظهر للنموذج مجموعة من الصور التي تحتوي على كرات برتقالية وزرقاء، مع تزويده بمعلومات توضح لون كل كرة في هذه الصور. من خلال هذه البيانات، يبدأ النموذج في التعرف على أنماط وسمات كل لون، مثل درجات الألوان المختلفة أو انعكاس الضوء على سطح الكرة.
بعد أن يتعلم النموذج هذه الأنماط، يُصبح قادرًا على تصنيف أي كرة جديدة لم يُشاهدها من قبل، وذلك بمجرد تحليل صورتها. تمامًا كما لو أننا دربنا شخصًا جديدًا على التمييز بين الألوان، لكنه هذه المرة نظام ذكاء اصطناعي يقوم بذلك بشكل تلقائي ودقيق.
هذه هي نفس الفكرة التي يعتمد عليها الذكاء الاصطناعي في تصنيف المحتوى الصحفي. النماذج الذكية تقرأ النصوص، تحللها، وتفرزها وفقًا لمعايير محددة مسبقًا، تمامًا كما تفعل الآلة في فرز الكرات.
أنواع نماذج التصنيفتتنوع نماذج التصنيف إلى عدة أنواع لكل منها دوره الخاص حسب طبيعة عملية التصنيف:
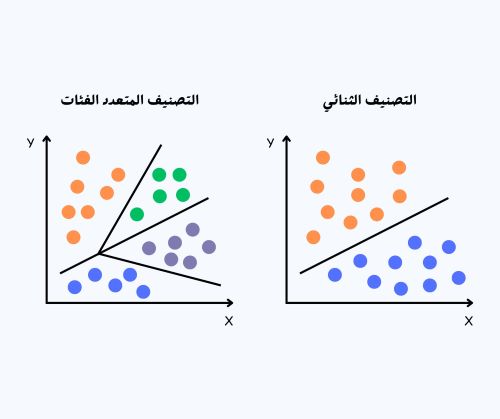 مخطط توضيحي يستعرض الفرق بين التصنيف الثنائي والتصنيف المتعدد، من تصميم عمرو العراقي.
مخطط توضيحي يستعرض الفرق بين التصنيف الثنائي والتصنيف المتعدد، من تصميم عمرو العراقي.
التصنيف الثنائي هو النوع الأول، حيث يتم تقسيم البيانات إلى فئتين فقط. يمكن استخدام هذا النموذج لتحديد ما إذا كانت المعلومات دقيقة أم غير دقيقة، أو إذا كانت التصريحات الصحفية تحمل طابعًا تحريضيًا أم لا. كما يساعد في تقييم مقالات الرأي لمعرفة ما إذا كانت تتماشى مع السياسات التحريرية للمؤسسة أم تخالفها. فهو يعمل دائمًا لتحديد تصنيف ونقيضه.
أما التصنيف المتعدد الفئات، فهو النوع الثاني الذي يُستخدم عندما تحتاج البيانات إلى تصنيفها ضمن أكثر من فئتين. على سبيل المثال، يُمكن تصنيف الموضوعات الصحفية حسب الأقسام التي تنتمي إليها، مثل السياسة، الاقتصاد، الرياضة، الثقافة، أو التكنولوجيا. هنا يكون الهدف هو اختيار الفئة الأنسب من بين مجموعة واسعة من التصنيفات.
النوع الثالث هو التصنيف متعدد التسمية، وفيه يمكن أن تنتمي المادة الصحفية الواحدة إلى أكثر من فئة في نفس الوقت. على سبيل المثال، قد يكون تقرير صحفي عن تأثير التكنولوجيا على الاقتصاد مرتبطًا بفئتين: "التكنولوجيا" و"الاقتصاد". هذا النوع من التصنيف يعكس الطبيعة المعقدة والمتشابكة للمحتوى الإعلامي الحديث.
تطبيقات لنماذج التصنيف في الإعلام
● تصنيف الأخبار بشكل أوتوماتيكي وفق الأقسام التحريرية
يمكن لنماذج تعلُم الآلة قراءة وتحليل الأخبار التي تأتي من مصادر مختلفة، ثم تصنيفها تلقائيًا إلى فئات مثل "سياسة"، "اقتصاد"، "رياضة"، "ثقافة"، مما يسهل على غرف الأخبار تنظيم المحتوى ونشره في القسم المناسب مباشرة أو إرساله إلى الفريق المعني للاطلاع عليه.
● تصنيف المعلومات الواردة من المصادر حسب دقتها
تساعد نماذج التصنيف في تحليل الأخبار وتقييم مصداقيتها من خلال دراسة مصدر الخبر، ونمط الكتابة المستخدم، ومدى تطابقه مع الحقائق الموثوقة. وبذلك، يُمكن للأنظمة الذكية تمييز المعلومات المغلوطة التي قد تحتوي على تحيّز أو تلاعب بالمعلومات، مما يمنح فرق التحقق الأدوات اللازمة لمراجعة المحتوى قبل نشره، وبالتالي الحد من انتشار المعلومات المغلوطة.
● تصنيف الصور حسب طبيعتها
لا تقتصر تطبيقات التصنيف في الإعلام على النصوص فحسب، بل تمتد أيضًا إلى المحتوى البصري، حيث يُمكن لأنظمة الذكاء الاصطناعي تحليل الصور وتصنيفها تلقائيًا استنادًا إلى محتواها. على سبيل المثال، يمكن تصنيف الصور وفق الفئات التالية: صور سياسية، صور رياضية، صور ترفيهية، ويُسهم هذا التصنيف في تنظيم الأرشيف البصري للصحف والمؤسسات الإعلامية، ويُسهل عملية البحث عن الصور المناسبة عند إعداد التقارير والمقالات الصحفية.
خطوات بناء النموذج
1- جمع البيانات
أول خطوة في بناء نموذج التصنيف هي جمع البيانات. الخطوة الأهم التي تؤسس لنجاح النموذج أو فشله. بدون بيانات غنية ومتنوعة، لن يكون النموذج قادرًا على التعلُم بشكل صحيح أو تقديم نتائج دقيقة.
في غرف الأخبار، يمكن جمع البيانات من مصادر متعددة، وكل مصدر يوفر نوعًا مختلفًا من المعلومات التي تُعزز قدرة النموذج على التمييز بين الأنماط المختلفة. منها على سبيل المثال:
● أرشيف الأخبار، الأرشيف غالبًا ما يكون مبوبًا بعدة طرق تسهل عملية التصنيف. على سبيل المثال، قد يتم تصنيف المواد الصحفية حسب القسم التحريري (مثل السياسة أو الاقتصاد)، أو باستخدام الكلمات المفتاحية التي تم إدراجها لتعزيز ظهور المادة على محركات البحث. بالإضافة إلى ذلك، قد تحتوي البيانات على أسماء كتاب المواد الصحفية، مما يساعد في تحديد الأنماط المرتبطة بأسلوب كل كاتب. هذه التبويبات تعتبر بمثابة دليل أولي لتعليم النموذج كيفية تصنيف الأخبار.
● بيانات وكالات الأنباء العالمية، مثل "رويترز" أو "أسوشيتد برس". عادةً ما تكون هذه البيانات مصحوبة بمعلومات تعريفية، مثل الموضوع الرئيسي للخبر، الموقع الجغرافي الذي يغطيه، أو حتى الجمهور المستهدف. هذه المعلومات يُمكن اعتبارها تبويبات جاهزة تساعد النموذج في فهم طبيعة كل مادة صحفية وتصنيفها بدقة.
● بيانات متاحة عبر الإنترنت ومصادر مفتوحة، في حال لم تكن المؤسسة الصحفية تمتلك أرشيفًا خاصًا بها، يمكن الاستناد إلى قواعد البيانات المتوفرة في مجتمعات علوم البيانات مثل "Kaggle". هذه المنصات توفر مجموعة كبيرة من البيانات التي يمكن استخدامها لتدريب النموذج. ومع ذلك، يجب التأكد من أن هذه البيانات تتناسب مع احتياجات المؤسسة وتتماشى مع طبيعة عملها.
كلما كانت البيانات أكثر تنوعًا، كان النموذج أكثر قدرة على التمييز بين الأنماط المختلفة للأخبار. التنوع في البيانات يعني شمولها لأنواع مختلفة من الأخبار، المصادر، والأساليب الكتابية، مما يُعزز من قدرة النموذج على التعامل مع الحالات الجديدة التي قد يواجهها أثناء العمل الفعلي.
2- معالجة البيانات
قبل الشروع في تدريب نموذج التصنيف، يجب التأكد من سلامة وجودة البيانات. هذه الخطوة حاسمة لأن أي أخطاء أو عدم تناسق في البيانات قد يؤدي إلى تشويش النموذج وتقليل دقته. على سبيل المثال، إذا قمت بإدخال البيانات يدويًا، فقد تواجه مشكلات مثل اختلاف طريقة كتابة التبويبات. فتصنيف "سياسة" قد يُكتب مرة كـ"سياسه" وأخرى كـ"سياسة"، وهنا يتعامل النموذج مع كل صيغة على أنها تصنيف مختلف تمامًا، مما يُسبب ارتباكًا في عملية التعلُم.
كذلك، قد تحتوي البيانات على مدخلات غير مبوبة، وهي المواد التي لم يتم تصنيفها بشكل صحيح أو لم يتم إرفاقها بعلامات تعريفية واضحة. هذه المدخلات قد تُربك النموذج أثناء عملية التعلُم، حيث لا يعرف كيفية التعامل معها. بالإضافة إلى ذلك، قد توجد بيانات مكررة بشكل متطابق، ولا فائدة من تكرارها لأنها لا تُضيف قيمة جديدة للنموذج. لذا، ينبغي التخلص من النسخ الزائدة والاحتفاظ بنسخة واحدة فقط من كل مادة.
تشمل عملية المعالجة المُسبقة للبيانات عدة خطوات أساسية. أولًا، إزالة القيم غير الصحيحة أو الفارغة، مثل الحقول التي لا تحتوي على بيانات أو تحتوي على معلومات غير مكتملة. ثانيًا، توحيد تنسيق النصوص لضمان اتساق البيانات؛ على سبيل المثال، توحيد طريقة كتابة التواريخ أو الأسماء. ثالثًا، التخلص من الأخبار المكررة لتجنب تحميل النموذج بمعلومات زائدة لا تُقدم له قيم لتحقيق كفاءة عالية في تنظيف البيانات.
3- تقسيم البيانات إلى مجموعات تدريب واختباربعد تنظيف البيانات ومعالجتها، تأتي خطوة حاسمة وهي تقسيم البيانات إلى مجموعتين: مجموعة التدريب ومجموعة الاختبار. الهدف من هذا التقسيم هو التأكد من أن النموذج لم يقم بحفظ البيانات كما هي، بل تعلّم الأنماط والعلاقات الأساسية التي تساعده على تصنيف بيانات جديدة بدقة. إذا اعتمد النموذج فقط على حفظ البيانات بدون فهمها، فإنه لن يكون قادرًا على التعامل مع حالات غير مألوفة عند تطبيقه في الواقع.
بيانات التدريب هي الجزء الأكبر من البيانات، وعادةً ما تشكل حوالي 80% من إجمالي البيانات. يتم استخدام هذه البيانات لتعليم النموذج كيفية التمييز بين الفئات المختلفة. كل نموذج تعلُم آلي يحتاج إلى بيانات مبوبة مسبقًا، أي أن كل نص أو مادة صحفية يجب أن يكون مرفقًا بتصنيف واضح يحدد الفئة التي ينتمي إليها. باستخدام هذه البيانات، يبدأ النموذج في استكشاف الأنماط والخصائص المميزة لكل فئة، مثل الكلمات المفتاحية المستخدمة في الأخبار السياسية أو الأسلوب الكتابي الخاص بالأخبار الرياضية. كلما كان حجم بيانات التدريب كبيرًا ومتوازنًا بين الفئات المختلفة، زادت قدرة النموذج على التعرف على الأنماط الدقيقة وتجنب الأخطاء.
أما بيانات الاختبار فهي النسبة المتبقية من البيانات، وعادةً ما تُخصص حوالي 20% منها لهذا الغرض. يتم الاحتفاظ بهذه البيانات بعيدًا عن النموذج أثناء عملية التدريب، بحيث لا يكون لها أي تأثير على تعليمه. بعد انتهاء التدريب، تُستخدم بيانات الاختبار لتقييم أداء النموذج ومعرفة مدى دقته في تصنيف الأخبار الجديدة التي لم يسبق له رؤيتها. هذه الخطوة ضرورية للتأكد من أن النموذج لا يكتفي بحفظ البيانات، بل يمتلك القدرة على التعميم واستخدام ما تعلّمه لحل مشكلات جديدة.
إذا كانت بعض الفئات ممثلة بشكل أقل بكثير من غيرها، فقد يؤدي ذلك إلى انحياز النموذج نحو الفئات الأكثر شيوعًا. على سبيل المثال، إذا كان هناك عدد كبير من الأخبار السياسية مقارنة بالأخبار الرياضية، فقد يميل النموذج إلى تصنيف معظم المواد على أنها سياسية حتى لو لم تكن كذلك. لتجنب هذا الانحياز، يجب التأكد من أن بيانات التدريب متوازنة بين الفئات المختلفة، أو استخدام تقنيات مثل إعادة التوزيع (Resampling) أو ترجيح الفئات (Weighting).
4- تدريب النموذج
بعد جمع البيانات ومعالجتها وتقسيمها إلى مجموعات تدريب واختبار، تأتي خطوة أساسية وهي اختيار الخوارزمية المناسبة لتدريب النموذج. هناك العديد من خوارزميات التصنيف التي يمكن استخدامها، وكل واحدة منها لها طريقة عمل خاصة بها ومجالات تطبيق مميزة. من بين أشهر هذه الخوارزميات:
- الانحدار اللوجستي (Logistic Regression):
الانحدار اللوجستي ليس مخصصًا فقط للتنبؤ بالقيم العددية، بل يستخدم بشكل شائع في التصنيف الثنائي. يعمل هذا النموذج عن طريق تقدير احتمالية انتماء العينة إلى فئة معينة بناءً على مجموعة من السمات.
- شجرة القرار (Decision Tree):
تعتمد هذه الخوارزمية على تقسيم البيانات إلى فروع متعددة بناءً على قواعد بسيطة. تعمل شجرة القرار كخريطة تُظهر كيفية اتخاذ القرارات بناءً على السمات المختلفة.
- الغابة العشوائية (Random Forest):
هي نسخة محسنة من شجرة القرار، حيث يتم إنشاء عدة أشجار قرار ودمج نتائجها للحصول على تصنيف أكثر دقة. الغابة العشوائية تُقلل من مشكلة التعقيد الزائد (Overfitting) التي قد تحدث عند استخدام شجرة قرار واحدة.
- آلة المتجهات الداعمة (Support Vector Machine, SVM):
تعمل هذه الخوارزمية على إيجاد حدود قرار (Decision Boundary) واضحة بين الفئات المختلفة. تُستخدم بشكل كبير في حالات التصنيف الثنائي، ولكن يمكن تطبيقها أيضًا على التصنيف المتعدد الفئات.
- الجيران الأقرب (K-Nearest Neighbors, KNN):
تعتمد هذه الخوارزمية على مبدأ الجار القريب، حيث يتم تصنيف العينة الجديدة بناءً على أقرب جيرانها في مجموعة البيانات. تُعتبر هذه الطريقة بسيطة وفعّالة، خاصة عند التعامل مع بيانات صغيرة أو متوسطة الحجم.
- نظرية بايز (Naive Bayes):
تستند هذه الخوارزمية إلى الاحتمالات والإحصاءات، وتعمل على افتراض أن السمات المستخدمة للتصنيف مستقلة عن بعضها البعض.
يفضل دائمًا، تجربة أكثر من خوارزمية واحدة على نفس مجموعة البيانات ومقارنة نتائجها باستخدام مقاييس الدقة مثل الدقة (Accuracy)، الاستدعاء (Recall)، والدقة المعدلة (Precision). هذا يساعد في تحديد الخوارزمية الأنسب لطبيعة البيانات والمهمة المطلوبة.
اختيار الخوارزمية المناسبة يعتمد على نوع البيانات وحجمها وتعقيدها، بالإضافة إلى الهدف المرجو من النموذج. تجربة واستكشاف عدة خوارزميات قد تكون الخطوة الأمثل لضمان تحقيق أفضل أداء ممكن.
5- تقييم أداء النموذج باستخدام مصفوفة الالتباس (Confusion Matrix)
بعد الانتهاء من تدريب النموذج، يُصبح من الضروري تقييم أدائه لمعرفة مدى دقته وفعاليته في تصنيف البيانات. هنا تأتي مصفوفة الالتباس (Confusion Matrix) كأداة أساسية لتقييم النموذج. هذه المصفوفة توفر صورة واضحة حول كيفية أداء النموذج من خلال مقارنة التوقعات التي قدمها مع القيم الحقيقية للبيانات.
تعرض مصفوفة الالتباس نتائج التصنيف في شكل جدول يوضح عدد الحالات التي تم تصنيفها بشكل صحيح وتلك التي صُنفت بشكل خاطئ. على سبيل المثال، إذا كان النموذج يقوم بتصنيف الأخبار إلى فئتين: "حقيقية" و"مزيفة"، فإن المصفوفة ستوضح عدد الأخبار الحقيقية التي تم تصنيفها بشكل صحيح، والأخبار الحقيقية التي تم تصنيفها خطأً على أنها مزيفة، والعكس بالنسبة للأخبار المزيفة.
من خلال هذه المصفوفة، يمكننا حساب مقاييس مهمة لتقييم الأداء، مثل الدقة (Accuracy) التي تمثل نسبة التصنيفات الصحيحة إلى إجمالي التصنيفات، والاستدعاء (Recall) الذي يقيس قدرة النموذج على استرجاع جميع الحالات الإيجابية الحقيقية، والدقة المعدلة (Precision) التي تشير إلى مدى دقة التصنيفات الإيجابية التي قدّمها النموذج. كما يتم استخدام F1-Score كمتوسط موزون بين الدقة والاستدعاء لتقديم صورة شاملة عن أداء النموذج.
6- حفظ النموذج واستدعاؤه لتصنيف نصوص جديدة
بمجرد أن يحقق النموذج مستوى عالٍ من الدقة والأداء المُرضي بعد عملية التدريب والتقييم، يتم حفظ النموذج ليكون جاهزًا للاستخدام العملي. هذه الخطوة تُعد محورية لأنها تُتيح استخدام النموذج بشكل مستمر بدون الحاجة لإعادة بنائه أو تدريبه في كل مرة. يتم حفظ النموذج بصيغة ملف يُمكن استدعاؤه بسهولة عند الحاجة، مما يجعله أداة فعالة وسريعة للتعامل مع البيانات الجديدة.
ملاحظات ختامية
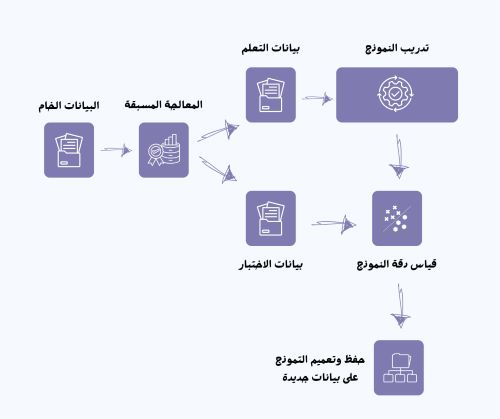
مخطط توضيحي يستعرض مراحل بناء نموذج التصنيف، من تصميم عمرو العراقي.
● يُعد تحقيق التوازن في بيانات التدريب أمرًا ضروريًا، حيث يمكن استخدام تقنيات مثل "Oversampling" و"Undersampling" لضمان عدالة التوزيع بين الفئات المختلفة، خاصة عندما تكون بعض الفئات ممثلة بشكل ضعيف.
● تقسيم البيانات إلى تدريب واختبار يتم تلقائيًا عبر الكود البرمجي لضمان عشوائية التوزيع وتجنب التحيز البشري.
● يُرمز إلى النصوص (الأخبار) بـ x وإلى عمود فئات التبويب بـ y في الكود البرمجي، مما يسهل فهم العلاقات الرياضية بين كلا المتغيرين.
● من الأفضل تجربة جميع خوارزميات التصنيف قبل اعتماد نموذج واحد، حيث قد يحقق أحد النماذج دقة عالية ولكنه يفتقر إلى القدرة على التعميم عند التعامل مع بيانات جديدة.
● الدقة وحدها ليست المعيار النهائي، فقد يحقق النموذج دقة مرتفعة ولكنه يعتمد على الحفظ بدلاً من الفهم الفعلي للأنماط في البيانات، مما يؤدي إلى أداء ضعيف عند تطبيقه على بيانات جديدة.
● الاختبار المستمر والتحديثات المستمرة ضرورية، فالمشهد الإعلامي متغير باستمرار، ويجب أن تتطور النماذج وفقًا لذلك للحفاظ على دقتها وفعاليتها.
الصورة الرئيسية مُولدة بالذكاء الاصطناعي بواسطة موقع image.fx.
إقرأوا المزيد من المقالات لـ
